.webp)
Trends
How to Calculate Your Sample Size Using a Sample Size Formula

.png)

.png)
Read More

.png)
.png)
Maria Noesi
November 25, 2021
Remesher
Trends
How to Calculate Your Sample Size Using a Sample Size Formula
Read More
November 25, 2021
Remesher
Trends
How to Calculate Your Sample Size Using a Sample Size Formula
Read More
November 25, 2021
Remesher
Trends
How to Calculate Your Sample Size Using a Sample Size Formula
Read More
November 25, 2021
Remesher
Trends
How to Calculate Your Sample Size Using a Sample Size Formula
Read More
November 25, 2021
Remesher
Trends
How to Calculate Your Sample Size Using a Sample Size Formula
Read More
November 25, 2021
Remesher
Natural Language Processing Applications in Market Research
Natural language processing (NLP) is essential to brands understanding their customers at scale, and can provide impactful insights from textual data.

In order to understand what your customers think about your brand, some sort of textual analysis is often required. Whether it be reviews on Yelp, press about your company, or even focus groups for customer feedback, the data is usually qualitative.
As Natural Language Processing (NLP) and machine learning algorithms become more sophisticated, it’s becoming easier to discover impactful insights from textual data.

What is Natural Language Processing?
NLP lives at the intersection of artificial intelligence, machine learning, and computational linguistics (Udemy, for example, has lots of educational courses is you want to know NLP better). The end goal of NLP is for a computer to analyze and generate natural language, meaning human generated language rather than artificial language or coding.
There are a number of familiar ways NLP is used to enhance the user experience.
For example, Gmail’s Smart Compose feature offers sentence completion suggestions by implementing a neural network model. Similarly, virtual assistants such as Siri and Alexa use speech recognition technology to craft their user experience.


Numerical Representation of Words
Being able to understand the numerical representation (the translation of language into a number that a computer can comprehend) of a word or sentence has always been crucial to NLP. Without these representations, data scientists would not be able to apply machine learning algorithms on textual data.

One of the major breakthroughs in NLP was when Google introduced Word2vec in 2013. Word2vec is a model that, in simple terms, converts words to numbers. These are known as word embeddings. Although the numerical representation of words and text have been around for a while now, Word2Vec was a big deal because it gave every word a unique representation.
Before Word2vec, a word that didn’t exist in an algorithm-trained NLP model would be tough for the model to understand.
For example, suppose we trained our model on three news articles about animals that use words such as “dog”, “cat”, and “frog.” If the model sees a new article that uses the words “snake” and “cow,” the model would not be able to predict that the article is about animals, since it has never seen “snake” and “cow” in an article about animals. Word2vec, on the other hand, would be more likely to understand that the article is about animals, because all words that can be defined as an animal would have similar numerical representations.
Application of Numerical Representations
Through these learned embeddings, you can better group similar words together. These simple yet extremely useful models are able to learn relationships such as “king” is to “queen” as “man” is to “woman.” With the success of word embeddings, research has extended into finding sentence embeddings. And these, of course, are numerical representations of sentences!

Pre-trained Language Models
Recently, pre-trained models have made many improvements upon word embeddings, which has made them more accurate in their use-cases.
But, wait, what is a pre-trained model?
Let’s imagine you want to bake a cake. You can either buy a premade cake mix from the store, or bake a cake from scratch. If you buy the premade cake mix, you can improve upon it by adding your own twist. You can add any frosting of your choice, or maybe some chocolate chips. Think of a pre-trained model in the same way: it is a model that someone else built to achieve a similar task that you are looking to solve.
Many of these transfer learning models - models that are re-used as a starting point for other problems that need a solution - have significantly improved the performance of word embeddings to understanding sentiment, to figure out if two texts are semantically similar, and to classify named entities (like person names, organizations, locations) through named-entity recognition.
Untapped qualitative data - which can be categorized using transfer learning models - exists all over the internet, which can be extremely helpful for market researchers - if they’re able to access it. During the 2012 elections, for example, the Obama administration used sentiment analysis to get a better idea of what the public thought of their campaign messages.
Pre-trained Language Models for Brands
As word embeddings advance, sentiment analysis and semantic similarity will continue to improve as well. This can be an incredible tool for researchers to better understand customer sentiment about a brand. It will also become easier for market researchers to automatically group together similar thoughts and find key thoughts in their customers reviews.
By speeding up the process of clustering responses into segments, brands can spend more time actually analyzing the data and coming up with valuable go-to-market strategies, improve customer experience, and create better campaigns.

Topic Modeling For Theme Detection
Topic modeling is a technique that enables researchers to discover themes from a large collection of documents or text. One method of topic modeling is Latent Dirichlet Allocation (LDA), which classifies documents into topics and words within documents to topics. LDA is a type of probabilistic clustering.
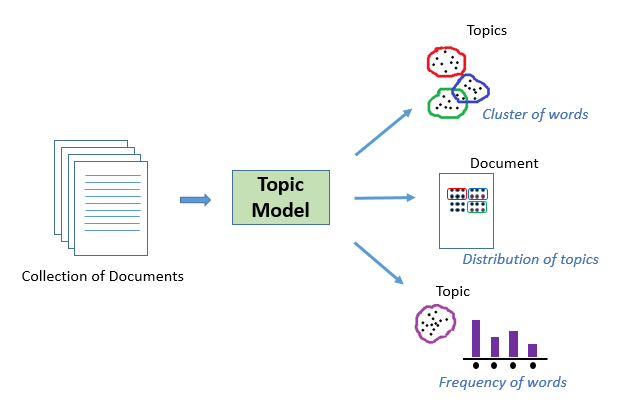
Probabilistic clustering is a form of clustering in which data points can belong to multiple groups. For example, a movie can be both an action movie and a comedy movie. In a similar sense, documents can have multiple themes.
The nature of topic modeling enables users to find hidden or unrecognized semantic structure in a text without a researcher manually surmising that structure. Historically, the applications of this statistical technique being applied for summarization of large textual documents.
Topic models, unfortunately, do not tend to be very successful when there is a small amount of text data; clustering via methods with word and sentence embedding often performs better. Even so, market researchers can discover insightful information by using topic modeling as an exploratory data analysis tool to understand their market and customers. Topic models, therefore, are often useful for registering brand mentions in news articles or customer reviews.
One benefit of using such algorithms is the elimination of bias -- rather than a researcher searching for specific topics they assume will manifest in data, a topic model will uncover the true topics within data.
The Importance of NLP in Market Research
Before methods in NLP became as sophisticated as they are today, researchers were required to go through more complex methods of acquiring qualitative data and significant results. They manually read through all responses, labeled responses, and grouped responses into categories.
NLP currently does not - and probably never will - be able to complete all the analysis for a focus group moderator or market researcher, but it can be used by market researchers to speed up what was once a tedious process.
We are saturated in textual data, all of which is essential for brands. Typically to understand your customers, you’ll need to hear what they write or what they say. Whether it is in a focus group, on social media, or on any customer review website, the data will likely be text. With methods in NLP becoming more and more sophisticated, it’s getting easier to analyze and get results.
Natural language processing is just one of the AI solutions disrupting market research. Discover the state of AI in the market by downloading our free eBook!
{{cta('4924012b-eaba-41b9-87de-f1de423074bb','justifycenter')}}


Stay up-to date.
Stay ahead of the curve. Get it all. Or get what suits you. Our 101 material is great if you’re used to working with an agency. Are you a seasoned pro? Sign up to receive just our advanced materials.
©All Rights Reserved 2024. Read our Privacy policy
